
Tables
Every data source configured in the Secberus platform, syncs API data into the Secberus data warehouse. This API data is normalized and stored in SQL database tables.
Table names are always prefixed with a short descriptor of the data source type from which the data was synced. For example, all AWS specific tables will have a prefix aws_, GCP tables gcp_, Okta tables okta_, etc. The rest of the table name is usually a corruption of the API endpoint used to gather the data. Continuing with the AWS example, the table aws_iam_users contains data that comes from the /iam/users API endpoint.
For most APIs each API endpoint is normalized into a single SQL table. Nested objects within the API responses are generally stored as JSONB fields in the database. You can learn more about JSONB tables and the various JSON specific functions here.
In the Data Explorer interface, the tables list is truncated to 100 elements. It is necessary to use the search/filter input at the top of the tables list to find the specific tables one might be looking for to construct a particular query. A good pattern to use is to start with the data source type prefix, then continue with the data type. this should reduce the table list to a much more usable subset.
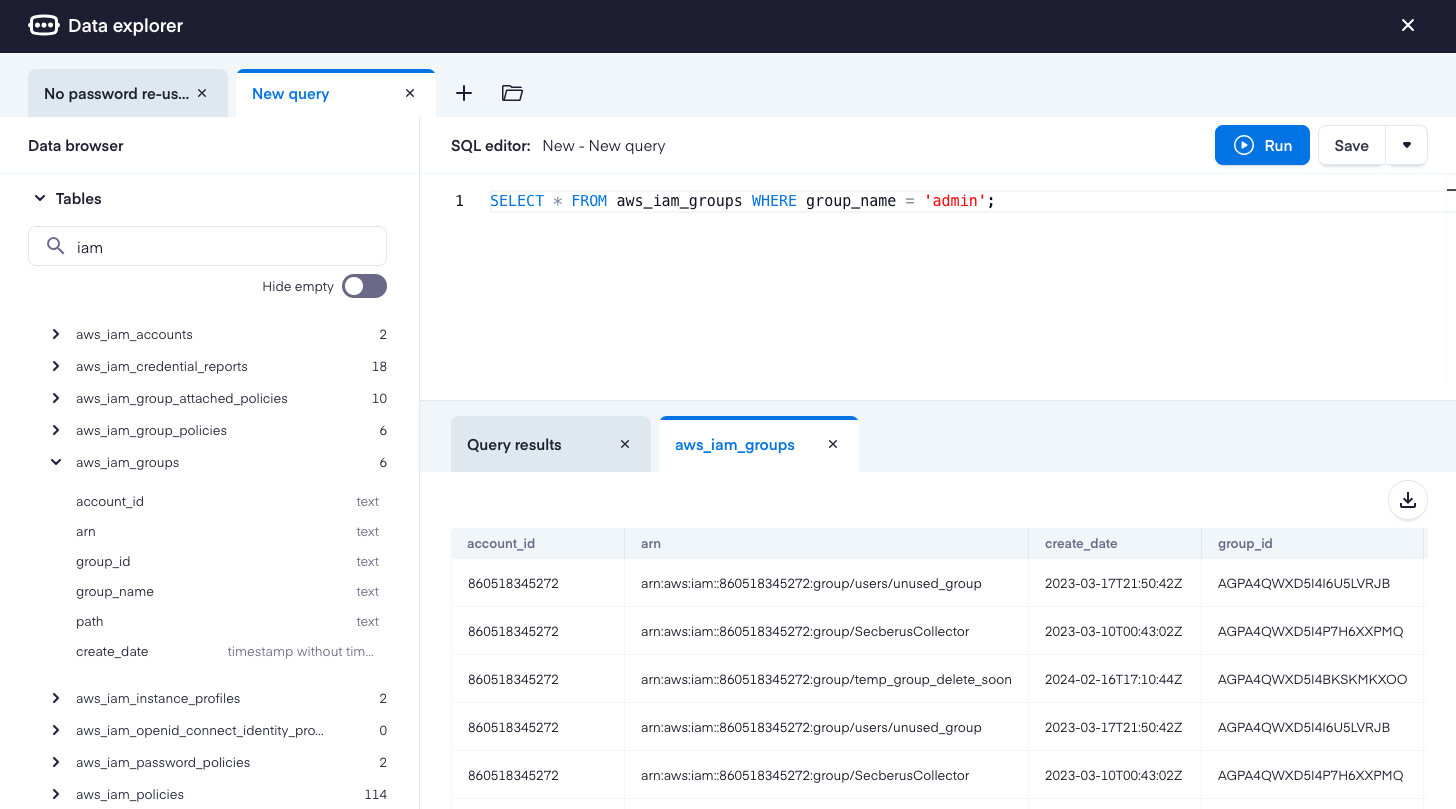
Clicking on a table name in the table list will expand details about the table under the table name in the list. Each column name along with its data type are shown below the table name in the lefthand list. It will also open a tab in the Query Results section of the view containing the contents of the table if there are any.
Tables are created automatically in the Secberus platform whenever a data source syncs data successfully for the first time. If you are expecting tables for a particular data source to be available but they do not show up in the Data Explorer, Go to Settings -> Data Sources and ensure the data source in question doesn't have any connection errors.

For more information on what data is stored in the Secberus tables/columns, reference the data source API documentation.
GCP: https://cloud.google.com/docs/
Azure: https://learn.microsoft.com/en-us/rest/api/azure/
AWS: https://docs.aws.amazon.com/
Okta: https://developer.okta.com/docs/api/
Cloudflare: https://developers.cloudflare.com/api/
Updated about 1 year ago